Some experiments at Wayfair can last 60 days or more. To speed up learning in experiments while still optimizing for long term rewards, our team developed a data science platform called Demeter, that uses ML models to forecast longer term KPIs based on customer activity in the short term. In this post we provide an overview for Demeter and its theoretical foundation in causal inference
11 Min Read



Experimentation plays a central role in understanding the business impact of data science strategies and solutions. A few weeks ago, Wayfair Data Science Manager Jerry Chen shared one way Wayfair has improved the experimentation process by building a unified test design and measurement platform (Gemini) for our marketing AB tests (read the blog post here!). In this video, Jerry will provide an introduction to running large scale Monte Carlo simulations to validate/optimize test design and measurement methodology using historical data.
1 Min Read
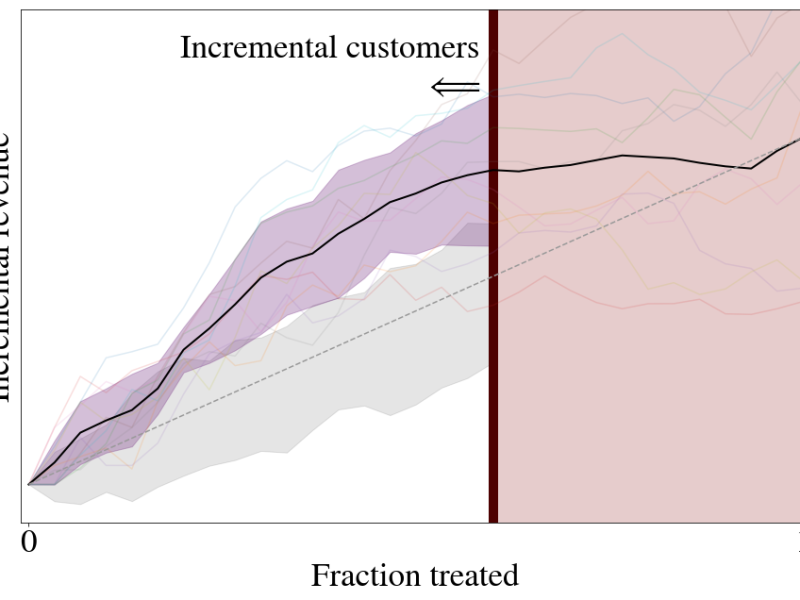

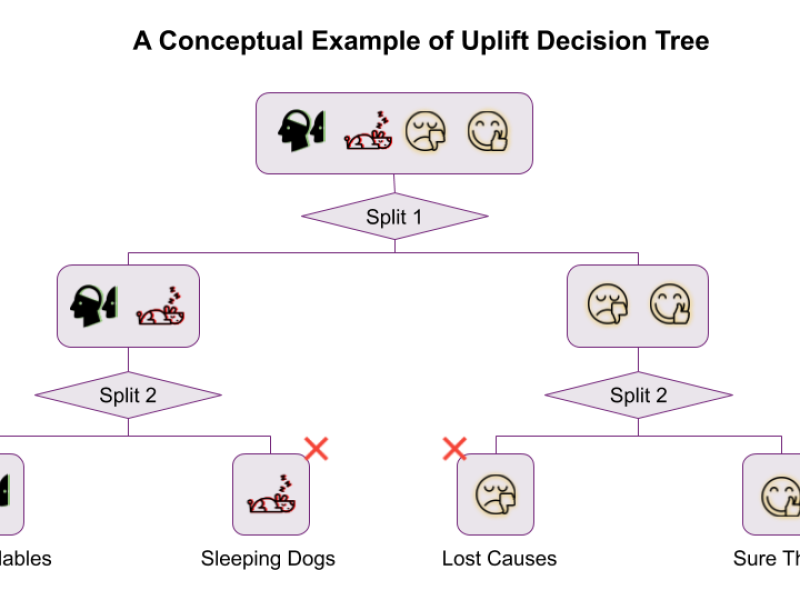
Uplift models seek to predict the incremental value attained in response to a treatment. For example, if we want to know the value of showing an advertisement to someone, typical response models will only tell us that a person is likely to purchase after being given an advertisement, though they may have been likely to purchase already. Uplift models will predict how much more likely they are to purchase after being shown the ad. The most scalable uplift modeling packages to date are theoretically rigorous, but, in practice, they can be prohibitively slow. We have written a Python package, pylift, that implements a transformative method wrapped around scikit-learn to allow for (1) quick implementation of uplift, (2) rigorous uplift evaluation, and (3) an extensible python-based framework for future uplift method implementations.
8 Min Read


As data scientists, we face a variety of problem types. One of our critical challenges is identifying the proper methodological approach to solve each problem. By doing this, we avoid force-fitting the wrong tool to solve a problem, and we avoid having to reformulate a question to fit a specific method.
2 Min Read